
LLMO, GEO oder GenAIO: Sichtbarkeit in der KI-Welt
ChatGPT statt Google. Gemini statt Produktsuche. Immer mehr Suchanfragen führen direkt zu KI-generierten Antworten – ohne Klick, ohne Website. Wer dort nicht erscheint, findet nicht statt. Dieser Ratgeber zeigt, wie Inhalte in diese Antworten gelangen – und was du dafür tun kannst.
Inhaltsverzeichnis
TL;DR – Das Wichtigste in Kürze
- LLMO ersetzt Rankings durch Nennungen: Sichtbarkeit entsteht in KI-Systemen wie ChatGPT, Perplexity oder Gemini über Erwähnungen – nicht über Platzierungen.
- Markensichtbarkeit wird zur neuen Währung: Häufige und konsistente Nennungen in hochwertigen, vertrauenswürdigen Quellen erhöhen die Chance auf Einbindung in KI-Antworten.
- Gartner warnt: Organischer Google-Traffic könnte bis 2028 um 50 % sinken – weil AI-Antworten keine Klicks mehr benötigen.
- Shift von Keywords zu Prompts: AI-Nutzer*innen stellen deutlich längere, spezifischere Fragen – im Schnitt 13+ Wörter statt klassischer Short-Tail-Keywords.
- Technik entscheidet mit: Schnelle Ladezeiten, offene robots.txt und strukturierte Inhalte bleiben Grundvoraussetzung für maschinenlesbare Inhalte.
- Monitoring bringt Licht ins Dunkel: Neue Tools analysieren Markennennungen, Zitierungen und Sichtbarkeit in AI-Antworten – wichtig für Strategie und Kontrolle.
- Früh starten lohnt sich: Wer jetzt optimiert, beeinflusst, wie LLMs Marken verstehen – und schafft langfristige Sichtbarkeit in der «Antwortwelt».
Dieser Ratgeber gibt keine schnellen Antworten, sondern Orientierung in einem Systemwandel. Er zeigt, wie Inhalte heute gedacht, geplant und geschrieben werden sollten, um auch morgen noch eine Rolle zu spielen – in einem Web, das nicht mehr nur durchsucht, sondern direkt generiert wird.
Zu Beginn ein paar Zahlen
Google ist als Suchmaschine mit rund 87% Marktanteil in der Schweiz und 90% weltweit mit Abstand führend – keine Frage [https://www.nzz.ch/technologie/googles-antwort-auf-chat-gpt-die-suchfunktion-uebersicht-mit-ki-kommt-nun-auch-in-die-schweiz-ld.1877137]. Aber die Nutzungsgewohnheiten verändern sich. Immer mehr Menschen suchen gar nicht mehr – sie fragen. Und das nicht nur bei Google, sondern bei ChatGPT, Perplexity oder anderen Large Language Models (LLMs) mit Chat- und Suchfunktion. Die Entwicklung scheint klar zu zeigen: Es ist nicht mehr die Frage ob, sondern vielmehr wann GenAI-Interfaces zur primären Anlaufstelle werden.
Dennoch gilt es den Hype auch kritisch zu reflektieren. Google hat im Frühling 2025 weltweit 4.3 Milliarden User und täglich 8.5 Milliarden Suchanfragen. ChatGPT kommt im gleichen Zeitraum auf rund 400 Millionen User. Die Angaben zu den Anzahl Anfragen pro Tag schwanken stark – am meisten genannt wird die Zahl 1 Milliarde.* Gehen wir von 8 Anfragen pro Chat aus und nehmen wir an, dass rund 30% davon effektiv eine Websuche beinhalten (Prozentangaben inspiriert durch einen LinkedIn-Post von Rand Fishkin), sind das 37.5 Millionen pro Tag. Im Vergleich zu Google sind das 0.4% oder 1/226. Selbst wenn es täglich 10 Milliarden Anfragen sind, kommt Google auf über 20x mehr als ChatGPT.
*Hinweis: Alle Angaben ohne Gewähr, da diese Zahlen von den Anbietern nicht öffentlich verifiziert wurden und die Berechnungen auf Annahmen basieren.
Dennoch gilt es eines festzuhalten: OpenAI hat mit ChatGPT bereits heute eine schier unfassbare Entwicklung hingelegt. Geht es so weiter – und danach scheint es auszusehen – kriegt Google als Suchmaschine tatsächlich ernsthafte Konkurrenz. Oder schafft Google vielleicht sogar den Turnaround und als Gewinner aus diesem Spiel hervorzugehen?

Eine neue Dynamik
Gemäss Malte Landwehr hat ChatGPT in Deutschland 4% Marktanteil und damit Bing mit 3% bereits überholt. Andere LLM Chatanbieter kommen erst auf Marktanteile von 0.x%, wachsen aber ebenfalls stark und lassen einige bekannte alternative Suchmaschinen zu Google, Bing und Yahoo schon hinter sich.
Google reagierte auf diese neue Konkurrenz. Zuerst verhalten und von vielen kritisch beurteilt, ja sogar belächelt – inzwischen aber mit eigenen LLMs, die weltweit in allen Bestenlisten auftauchen. Die neue Dynamik im Suchmarkt führt dazu, dass sich nicht nur die reine Informationssuche verändert, sondern auch der Bereich E-Commerce. Kurz nachdem ChatGPT Shopping einführte [https://help.openai.com/en/articles/11128490-improved-shopping-results-from-chatgpt-search] zog Google nach [https://blog.google/products/shopping/google-shopping-ai-mode-virtual-try-on-update].
Vielleicht wurde es auch langsam Zeit für eine echte Veränderungen. Die 10 blauen Links waren bekanntlich über Jahre hinweg der Standard. Doch ist diese Auswahl wirklich das Maximum an Userfreundlichkeit?
LLMs zeigen, wohin es gehen könnte. Weg von Links und «hilf dir selbst» hin zu direkten Antworten und echter Hilfe für die Suchenden. Das Ganze über ein Chatinterface, das sich intuitiv bedienen lässt und sich dabei auch irgendwie menschlicher anfühlt.
Vor diesem Hintergrund startete Google im Mai 2023 in den USA die Search Generative Experience (SGE). Ein Jahr später wurden daraus die AI Overviews. Am 26. März 2025 kam auch Europa in den Genuss dieser Weiterentwicklung.
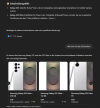
Noch weiter geht Google in den USA im Bereich der investigativen Suche. So liefern sie im Fall eines Vergleichs von zwei Handys nach dem Klick auf «See full comparison» eine tabellarische Auswertung von 18+3=21 (!) Quellen.
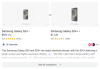
Und kaum sind die AI Overviews bei uns gelauncht, zeigt Google am 21. Mai 2025 an der Google I/O, wie ein neuer sogenannter AI Mode in der Suche integriert wird [https://io.google/2025/explore/google-keynote-1][https://blog.google/technology/ai/google-io-2025-all-our-announcements/]. Gestartet in den USA, wird dieser vermutlich mit einigen Monaten Verzögerung auch wieder in Europa ankommen.
Die Suche im Internet verändert sich. Diese neue Dynamik ist spürbar und für alle Internetuser erlebbar. Viele fragen sich was das verändert? Wie kommen die Suchergebnisse zustande? Und ganz konkret: Wie schaffe ich es, in diesen generierten Antworten selbst zu erscheinen? Um genau diese Fragen geht es im weiteren Verlauf dieses Artikels.
Von SEO zu LLMO: Begrifflichkeiten
Seit Jahren optimieren wir Inhalte für die klassische Google-Suche: Keywords, technische Struktur, E-E-A-T (Expertise, Erfahrung, Autorität und Trust, also Vertrauen) und wenn es ein Projekt zwingend erfordert auch Backlinks – das ganze Arsenal klassischer SEO-Massnahmen. Dieses Spiel verändert sich. KI-Modelle wie ChatGPT oder Gemini funktionieren anders – sie geben Antworten statt Links.
LLMO – also die Optimierung für Large Language Models – ist nur der nächste logische Schritt. Doch was bedeutet der Begriff eigentlich und was ist mit den verwandten Begrifflichkeiten GEO, GENAIO oder weiteren Alternativen, wie AIMO, MO oder AIO?
Was ist LLMO?
LLMO beschreibt alle Massnahmen, die darauf abzielen, Inhalte, Marken oder Produkte so zu gestalten, dass sie in den Antworten generativer KI-Modelle genannt, zitiert oder empfohlen werden. Es geht nicht mehr nur um Rankings – sondern darum, Teil der generierten Antwort zu sein.
Was ist GEO?
GEO steht für Generative Engine Optimization – ein alternativer Begriff, der den Fokus nicht auf das Modell (LLM), sondern auf das Gesamtsystem der Generierung legt [https://searchengineland.com/what-is-generative-engine-optimization-geo-444418] [https://en.wikipedia.org/wiki/Generative_engine_optimization].
Was ist GenAIO?
GenAIO (Generative AI Optimization) ist der wohl breiteste Begriff – und gleichzeitig der unschärfste. Er umfasst die Optimierung für alle Arten von generativer KI, also nicht nur Textmodelle, sondern auch Bild-, Audio- oder Multimodal-Modelle.
Weitere Alternativen?
Die verschiedenen Bezeichnungen LLMO, GEO oder GenAIO konkurrieren – je nachdem, ob der Fokus stärker auf den Modellen (Large Language Models), den generativen Systemen insgesamt oder der KI im weiteren Sinne liegt. Auch völlig andere Ideen stehen im Raum: AIMO für AI Model Optimization, AMO für Answer Machine Optimization oder einfach AIO für AI Optimization.
Intern bei uns sowie auf LinkedIn gibt es auch Stimmen, alles unter dem bekannten Begriff SEO weiterzuführen – schliesslich ist auch Google inzwischen eine KI-gesteuerte Antwortmaschine.
Wie sich die Terminologie entwickelt, wird sich zeigen. Aktuell aber spricht vieles dafür, das Phänomen beim Namen zu nennen: Es geht um die Sichtbarkeit in Large Language Models.
LLMO ist deshalb der Begriff, den wir in diesem Ratgeber verwenden – weil er das präzise beschreibt, worum es aktuell geht.
Vergleich SEO vs. LLMO
Gute Inhalte bleiben gute Inhalte. Auch in der KI-Welt. Doch die Mechanik dahinter verändert sich. Sichtbarkeit entsteht nicht mehr ausschliesslich durch Rankings, sondern durch die Relevanz im Kontext generativer Modelle. KI-Modelle funktionieren anders als klassische Suchmaschinen.
- Relevanz wird zu Kontext: Keywords allein reichen auch in LLMs nicht. Es geht um semantische Nähe, Kookkurrenzen und Entitäten – also darum, wie Begriffe, Marken und Themen miteinander in Beziehung stehen. Gut, um ehrlich zu sein: Wer in den letzten Jahren SEO rein als Spiel mit Keywords verstanden hat, war schon da nicht besonders zukunftsfähig. Trotzdem: Auch einfache Massnahmen, wie Titles oder strukturierte Inhalte, können weiterhin wirken – jetzt einfach in einem neuen System.
- Ranking wird zur Nennung: In einem LLM gibt es keine Resultatseite mit Position 1 bis 10. Entscheidend ist, ob die eigene Market erwähnt wird – in Antworten oder als Quelle.
- Menschen bleiben das Ziel – Maschinen entscheiden mit: Inhalte werden weiterhin für Menschen gemacht. Doch je maschinenlesbarer, strukturierter und kontextbezogener sie sind, desto höher ist die Chance, dass sie in LLM-Antworten auftauchen.
- SEO bleibt als Basis relevant – und wird nun Teil eines grösseren Ganzen: Technische Optimierung, Ladezeiten, E-E-A-T: All das bleibt wichtig. Aber es reicht nicht mehr. Sichtbarkeit entsteht durch ein Zusammenspiel aus inhaltlicher Qualität + semantischem Kontext + maschinenfreundlicher Struktur.
| Dimension | Klassische SEO | LLMO |
|---|---|---|
| Ziel | Klick auf Website via Google | Erwähnung in KI-Antwort (Text, Zitat, Quelle, Link) |
| Content-Fokus | Keywords, Snippets, Onpage-Optimierung | Entitäten, Prompts, Kontextverständnis |
| Technischer Fokus | Crawlbarkeit für Googlebot | Crawlbarkeit für KI-Bots (z. B. CCBot, Bingbot, GPTBot) |
| Strukturierung | Meta-Tags, H1-H3, strukturierte Daten | Listen, FAQs, klare Gliederung, maschinenlesbare Argumentation |
| Autoritätssignale | Backlinks, Domain Authority | Markennennungen, Zitierfähigkeit, Reputationsquellen |
| Analyse-Tools | GSC, Sistrix, Semrush | Otterly, Peec, Profound, eigene Prompt-Tests |
| Reaktionsgeschwindigkeit | Hoch (nach Indexierung) | Langsam bis nie bei reinen LLMs (Foundational Models), schnell bei KI-Search (Retrieval Augmented Generation) |
| Einflussnahme | Über eigene Inhalte und Content Marketing | Indirekt über genannte Quellen, Entitäten, Erwähnungen, PR |
| User Experience | Einfluss auf CTR, Bounce Rate, Rankings | Noch unklar, aber mutmasslich zunehmend relevant |
Bei all diesen Veränderungen bleibt eines gleich – der Informationsbedarf der Menschen. In LLMs macht die Informationssuche aktuell den grössten Teil aus. Weiter dazu kommt die Unterstützung beim Schreiben, Programmieren, bei der Produktsuche, bei Hausaufgaben und Prüfungen. Noch eher selten geht es ums Generieren von Bildern oder Videos.
Für uns besonders eindrücklich sind Berichte aus unserem Umfeld und aus dem Publikum bei Vorträgen. Dabei geht klar hervor, dass viele Menschen in Chats mit den LLMs Geheimnisse preisgeben, die sie nicht mal ihren Freunden, der Familie oder Fachpersonen erzählen würden. Das ist vielleicht bedenklich aber irgendwo auch verständlich. Die Probleme und Fragen sind da. Wer will schon 4 bezahlte, dann 10 blaue und nochmals 3 bezahlte Links, wenn es direkt Hilfe von einer neutralen Instanz gibt, die zudem immer ein offenes Ohr hat? Websitebesuche werden damit zunehmend unnötiger. Die benötigten Antworten werden aus den LLMs zusammen mit dabei ausgelösten Websuchen und deren Ergebnissen generiert. Die Websites selbst werden selten oder überhaupt nicht mehr besucht.
Für gewisse Websitebetreiber hat dies gravierende Konsequenzen. Schon heute führen rund 60% aller Suchen zu keinen Klicks – die eine Hälfte davon endet einfach so, die andere löst eine weitere Suche aus. Also führen nur 40% aller Suchen effektiv zu Klicks. Seit der Einführung der AI Overviews ist der Traffic bei entsprechenden Suchanfragen um weitere 15% bis zu über 60% zurückgegangen. Im Durchschnitt liegen die Werte in Tests von Dritten bei rund 40% Rückgang. So hohe Zahlen können wir im Moment ausgehend von unseren Kundendomains nicht bestätigen, sehen den Effekt aber auch bereits.
Noch deutlich beeindruckender sind erste Zahlen zu den LLMs. Suchen in Perplexity führen nur in 20% zu Klicks. Solche in ChatGPT nur zu 2%.

Gartner wagte hierzu eine Prognose: Bis 2028 soll der organic Traffic um 50% geringer ausfallen. In Anbetracht der genannten Zahlen scheint dieser Wert geradezu optimistisch.
Heisst das nun zum 101. und vielleicht letzten Mal, SEO ist tot? Nein. Aber SEO verändert sich. Wieder einmal. Diesmal vielleicht grundlegender als sonst – aber im Kern bleibt es ein vertrautes Spiel.
Echte Daten von unseren Kunden
Immer wieder wird gesagt, dass die AI Overviews (AIO) viele Websites in den Ruin treiben und kein Traffic mehr auf die Seite kommt. Wir wollten wissen, wie die Lage wirklich aussieht, und haben dafür Daten von einigen unserer Kunden aggregiert und aufbereitet.
Das «Krokodil» zwischen Impressions und Klicks
In der Diskussion wird häufig vom «Krokodil» gesprochen: steigende Impressions auf der einen Seite, sinkende Klicks auf der anderen. Und einer stark sinkenden Click Through Rate (CTR). Dieses auseinanderklaffen der zwei Metriken, ähnelt dem Mund von einem Krokodil.

Und wie sehen unsere Daten aus? Ja, die CTR sinkt tatsächlich auch bei unseren Kunden. Doch woran liegt dies?
Auch wir sehen stark steigende Impressions. Dies ist gut erklärbar, da mit den AI-Overviews die Anzahl gezeigter Verlinkungen stark gestiegen ist. Es gibt nicht mehr nur 10 Links, sondern ein x-faches an zusätzlichen Links in den Texten der AIO.
Und wie sieht es mit den Klicks aus? Im Gegensatz zum (vermeintlichen) Tenor sehen wir bei unseren Kunden eher eine leicht steigende Tendenz bei den Klicks. Diese steigen jedoch weit weniger als die Impressions, was zu einer sinkenden CTR führt. Weniger Klicks geteilt durch mehr Impressions führen auch zu einer sinkenden CTR. Doch nun fällt die Interpretation anders aus.
Aufgrund dieser Beobachtungen erhalten wir im Grunde mehr Klicks und deutlich mehr Sichtbarkeit in den Suchergebnissen (SERP). Grundsätzlich ist dies eine sehr gute Entwicklung. Ob dies so bleibt und bei deiner Seite ebenfalls so ausfällt, muss im Einzelfall betrachtet werden. Einen Bias haben unsere Daten sicherlich, da (fast) alle unsere Kunden im betrachteten Sample aktiv SEO betreiben. ;)


Click Through Rate erklärt
Die CTR (Click-Through-Rate) zeigt, wie häufig ein Suchergebnis oder eine Anzeige nach einer Einblendung tatsächlich angeklickt wird. Sie berechnet sich aus dem Verhältnis von Klicks zu Impressions:
CTR = Klicks ÷ Impressions × 100 %
Steigen die Impressions (also wie oft dein Ergebnis gesehen wurde), während die Klicks gleichzeitig zurückgehen, sinkt rechnerisch die CTR. Das ist ein häufiges Muster, etwa wenn neue, weniger relevante Suchanfragen Reichweite bringen, dein Snippet an Position verliert oder die SERP mehr ablenkende Elemente enthält.
Mini-Beispiel:
Monat A: 1 000 Impressions, 100 Klicks → CTR = 10 %
Monat B: 2 000 Impressions, 120 Klicks → CTR = 6 %
Obwohl die Klicks absolut leicht gestiegen sind (100 → 120), ist die CTR gesunken (10 % → 6 %), weil die Impressions stärker gewachsen sind. Umgekehrt gilt: Bleiben die Impressions konstant und die Klicks fallen, sinkt die CTR ebenfalls.
Praktischer Schluss: Eine sinkende CTR ist nicht automatisch „schlecht“, sie kann z. B. mit breiterer Sichtbarkeit in weniger klickstarken Bereichen einhergehen. Wichtig ist, parallel die Positionen, Suchbegriffe (Intent/Relevanz) sowie Snippet-Elemente (Title, Meta-Description, Rich Results) zu prüfen und gezielt zu optimieren.
Mehr Sichtbarkeit durch AIO
Unsere Auswertungen zeigen auch, dass AIO nicht per se schlecht für den organischen Traffic sind, sondern in erster Linie für viel mehr Impressionen sorgen. Wie viele Klicks (und Conversions) erzielt werden, ist Stand heute (Oktober 2025) nicht präzise messbar, da Google die Daten nicht spezifisch ausweist.
Eigene Daten sind entscheidend
Auch wenn wir tendenziell zu einem positiven Ergebnis kommen, variiert die Situation von Kunde zu Kunde. Wie immer ist es entscheidend, die eigenen Daten zu kennen und diese selbst auszuwerten. Unser Tipp ist: Verwaltet und kontrolliert eure Daten, sei es über BigQuery oder andere Datenbanken. Wertet diese regelmässig aus und erstellt Reports. Je nach Situation lohnt sich auch ein Alerting, um bei Schwankungen zeitnah Massnahmen zu ergreifen.
AI Overviews messen
AI Overviews (AIO) werden (Stand: Oktober 2025) von Google nicht offiziell separat gemessen. Klicks und Impressionen werden zwar in den Auswertungen der Google Search Console ausgewiesen, eine separate Auswertung der Performance ist jedoch nicht möglich. Somit bleibt unklar, wie viel Traffic (und Impressionen) über die AIO erzielt wird.
Es gibt jedoch einen Workaround, um den Traffic mehr oder weniger genau zu bestimmen. Mithilfe von URL-Fragmenten kann sogar angenähert erkannt werden, welche Abschnitte in den AI-Overviews erscheinen. Google hängt bei Snippet-/AIO-Klicks oft ein Scroll-to-Text-Fragment an (#:~:text=…). Dieses Fragment führt direkt zum hervorgehobenen Textabschnitt und kann als Signal in GA4 erfasst werden. So ist es möglich, nicht nur die Anzahl der Klicks aus AIO abzuschätzen, sondern auch zu sehen, welche Absätze und Texte vor allem von LLMs (Google) als relevant betrachtet werden.
Diese werden nicht standardmässig erfasst und im GA4 herausgefiltert (daher ist die Suche im GA4 erfolglos), doch können diese als benutzerdefinierte Variable in Google Tag Manager (GTM) hinterlegt werden. Mit ein bisschen Custom JavaScript können die Fragmente erfasst und geordnet werden. Dies erlaubt uns die Anzahl und die Abschnitte zu erkennen, die von AIO kommen.
Achtung Limitation: Nicht nur AIO können diese Fragmente generieren. Google benutzt diese Fragmente auch bei anderen Featured Snippet und auch wir (User) können solche Fragmente erstellen, wenn wir spezifische Absätze als Link weiterschicken (z.B. im Chrome-Browser: Text markieren, linke Maustaste draufklicken und «Link zu markiertem Text kopieren» wählen) . Zusätzlich haben nicht alle Links in den AIO solche Text-Fragmente – wenn ganze Seiten zitiert werden, haben die Verlinkungen aus den AIO keine Fragmente. Diese Methode bleibt daher eine Annäherung – aber die beste, die wir im Moment haben.
E chli Wärbig
Neugierig geworden?
Wir stören ungern – na gut, vielleicht ein bisschen. Aber hey, wenn du schon da bist: Hol dir mehr Wissen und Wirkung – oder einfach ein bisschen iqual in dein Leben. Klick dich rein – oder lies unten weiter.



Googlet Chat GPT?
Als vermutlich erster äusserte Alexis Rylko in seinem Blog die Vermutung, dass ChatGPT auf Google-Suchergebnisse zurückgreift [https://newsletter.alekseo.com/p/searchgpt-bing-google]. Er stellte fest, dass die Ergebnisse von ChatGPT zu 90 % mit den Google-Suchergebnissen (SERP) übereinstimmen. Doch war das schlicht Zufall?
Uns ist noch etwas anderes aufgefallen. Der Parameter ?SRSLTID= in URLs steht für «Search Result Set ID» und ist eine eindeutige Kennung von Google. Er dient Google zur Analyse des Nutzerverhaltens, um die Qualität und Relevanz der Suchergebnisse zu verbessern. Und siehe da, dieser eindeutige Parameter erscheint in den Verlinkungen von ChatGPT. Dies nennt sich dann wohl eine «Smoking Gun».
Was bedeutet das für unsere tägliche SEO-Arbeit? Seit 2010 optimieren wir Webinhalte primär für Menschen und nicht für Google. Nun helfen wir einer Maschine (ChatGPT mit Websuche), die richtigen Inhalte für Menschen über eine andere Maschine (Google) zu finden. Wir betreiben also tatsächlich Suchmaschinenoptimierung - Pure Ironie.
Zusammenfassend: Nein, SEO ist nicht tot. Aber SEO ändert sich – wie schon seit immer.
Sichtbarkeit in LLM-Antworten
In klassischen Suchmaschinen ist Sichtbarkeit gleichbedeutend mit einem Top-Ranking. In der Welt der LLMs funktioniert das anders: Sichtbar ist, wer erwähnt wird – in der Antwort selbst oder als eingeblendete Quelle. Und das passiert nicht zufällig.
LLMs arbeiten mit Wahrscheinlichkeiten, Kontexten und semantischer Nähe. Sie rekonstruieren Antworten auf Basis riesiger Datenmengen – entweder aus ihrem internen Gedächtnis (Foundational Model) oder durch den Zugriff auf externe Quellen z.B. über eine eingebaute Suchmaschine via Retrieval Augmented Generation (RAG) [https://research.ibm.com/blog/retrieval-augmented-generation-RAG][https://aws.amazon.com/what-is/retrieval-augmented-generation/]. Diese Unterscheidung ist zentral und wird nachfolgend erläutert.
Foundational Models
Vereinfacht ausgedrückt hat ein Foundational Model ausgelernt. Es greift nur auf Wissen in der Vergangenheit zurück, das es bis zu einem bestimmten Zeitpunkt gelernt hat. Zentral sind dabei die verwendeten Quellen und Gewichtungsfaktoren. So wurde GPT3 angeblich mit Daten aus Common Crawl (1x), OpenWebText2 (6x), Wikipedia (5x) und Büchern (1.4x) trainiert.
Dies führt ohne Grounding (also das «Verifizieren» der Antwort z.B. mit einer Websuche und Auswertung der Resultate) mitunter zu unterhaltsamen Chats, wie die veraltete Antwort auf die Frage nach den sieben Bundesräten zeigt. Es wirkt fast so, als ob ChatGPT «wüsste», dass die Antwort falsch ist, die richtige aber nicht nachschlagen kann bzw. in diesem Fall nicht darf.

Wie genau die heutigen LLMs trainiert werden und was für Informationsquellen und Gewichtungsfaktoren dabei verwendet wird, ist mit wenigen Ausnahmen ein gut gehütetes Geheimnis der LLM-Anbieter.
Wer in einem einmalig oder alle paar Monate bis Jahre neu trainierten Foundational Model vorkommen will, muss dafür sagen, dass die eigenen Informationen in einen Trainingsdatensatz gelangen. Dieses Unterfangen gestaltet sich schwierig. Autorität und Popularität sind sicher wichtig. Doch gehört auch Glück dazu.
Nebst Glück gehört auch dazu, dass den Bots der LLM-Betreibenden die Suche nach Trainingsdaten erlaubt und möglichst einfach gemacht wird. Bots also nicht aussperren und Webinhalte serverseitig so aufbereiten, dass LLM-Bots sie rendern können. Dies gilt auch oder insbesondere für RAGs.
Retrieval Augmented Models (RAGs)
Wenn LLMs Antworten verifizieren, also ein Grounding machen, führen sie z.B. eine Websuche durch und werten die dabei gefundenen Informationen aus. Es geht also darum zu erreichen, dass eine angestossene Websuche die eigenen Informationen findet und dann als Quelle berücksichtigt.
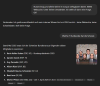
Wer in LLMs gefunden werden will, muss also in den von den RAGs genutzten Suchmaschinen «ranken». Ein top Ranking in Bing hilft demzufolge in ChatGPT, während eines in Google für Gemini oder die AI Overviews nützlich ist.
Wie genau diese Zusammenhänge funktionieren, ist aktuell noch wenig bekannt und Teil von laufenden Experimenten. Erste Ergebnisse zeigen, dass SEO quasi die Grundvoraussetzung ist, um LLMO zu betreiben [https://ziptie.dev/blog/seo-still-matters-for-ai-search-engines/]. Irgendwie ist es Ironie pur, dass es in der nächsten Evolution von SEO nun wirklich um die Optimierung für Suchmaschinen geht und für einmal nicht um die User. Denn diesmal suchen keine Menschen, sondern die Bots der LLM-Betreibenden.
Wurde eine Website so gefunden, geht es darum, die darauf vorkommenden Inhalte zu crawlen, zu rendern und auszuwerten. Ist einem konkreten LLM-Bot ein Webbesuch erlaubt und werden Webinhalte LLM-Bot-freundlich angeboten, steht diesem Vorhaben nichts wesentliches entgegen. Werden Bots aber absichtlich oder wider besseren Wissens ausgeschlossen, funktioniert dies nicht. Dasselbe gilt für vollständig clientseitig gerenderte Webinhalte. Bots, die mit solchen Technologien (noch?) nicht umgehen können, erhalten beim Aufruf einer entsprechenden URL nichts inhaltlich verwertbares und damit ist diese Chance vertan.
Ein Beispiel verdeutlich dies: Während Google heute sehr gut in der Lage ist, JavaScript zu interpretieren und mit clientseitig gerenderten Websites kaum noch Mühe hat, sieht dies bei Bing anders aus. Dies durften wir jüngst wieder in einem Kundenprojekt erfahren, bei dem Bing ausser der Meta Description nichts richtig gerendert kriegte – Fehlermeldungen gab es keine, weil die URL ja ganz normal aufgerufen werden kann. Einzig die immer gleichen Seitentitel einer pre-rendering-Version fielen irgendwann auf.
Da Bing gemäss Aussagen von OpenAI für die Websuche genutzt wird, spricht dies stark für den Einsatz entsprechender Webtechnologien bzw. das serverseitige Rendering zumindest der zentralen Inhalte einer Website. Und weiter? Nun kommt es auf die gefundenen Inhalte an.
Was macht Inhalte LLM-relevant?
LLMs bevorzugen Inhalte, die sich klar, strukturiert und maschinenlesbar präsentieren. Je besser ein Modell den Kontext versteht, Einheiten extrahieren und Beziehungen herstellen kann, desto grösser ist die Wahrscheinlichkeit, dass solche Inhalte in einer Antwort auftauchen. Was hilft:
- Klare Struktur: Überschriften als H2/H3, Listenelemente, FAQs
- Starke Begriffe: Definitionen, Vergleiche, Modelle
- Eindeutige Sprache: Geschwurbel und Worthülsen weglassen
- Eigene Haltung: nicht nur Wiederkäuen, klar erkennbare Expertise
- Zitate & Belege: Quellen nennen und kurze 1-2 Satz Zitate, Statistiken
- Kontext mit einbauen: Thema|Produkt + Marke gemeinsam nennen
Ein Mass, um die inhaltliche Passgenauigkeit zu bestimmen, ist die Cosine Similarity. Das klingt nach Mathematikunterricht – und ist es im Kern auch [https://myscale.com/blog/cosine-similarity-revolutionizing-llm-performance-metrics/]. Der Begriff stammt aus der Vektorrechnung und beschreibt die Ähnlichkeit zwischen zwei Texten anhand ihres inhaltlichen und semantischen Abstands im Raum der Sprachmodelle. Einfacher gesagt: Je näher ein Text an dem liegt, was ein Sprachmodell als passende Antwort generiert, desto höher ist die Wahrscheinlichkeit, dass er eingeblendet oder zitiert wird.
In der Praxis spielte das beispielsweise bei Googles Search Generative Experience (SGE) oder den heutigen AI Overviews eine gewisse Rolle. Inhalte, die in Aufbau, Wortwahl und Kontext stark von der LLM-Antwort abweichen, werden angeblich seltener übernommen – oder durch näherliegende ersetzt. Ein mögliches Indiz: Google schreibt die Meta Description automatisch um. Das kann auf eine zu geringe semantische Übereinstimmung hinweisen.
Erste eigene Beobachtungen zeigen, dass eine hohe Cosine Similarity zwischen Antwort und Webseite gerade im Fall von AI Overviews nicht in jedem Fall gegeben ist. Manchmal passt es haargenau, in anderen Fällen überhaupt nicht. Der mathematische Ansatz ist also konzeptionell spannend, in der Praxis aber kritisch zu prüfen. Das erinnert in der klassischen SEO an die wdf*idf Diskussionen im Jahr 2012 oder 2013. Letztlich nützt es nie etwas, Texte stumpf nach diesen Metriken zu optimieren. Manchmal zeigt es aber auch ganz grundsätzlich auf, dass ein Text schlicht an der Suchintention vorbeigeschrieben wurde. Es fehlten nicht einzelne Wörter, sondern ein zentraler Grundgedanke, den alle zu diesem Thema erwarten.
LLMO zielt also nicht nur auf inhaltliche Relevanz, sondern auf semantische Nähe. Tools wie Sistrix oder termlabs.io können helfen, diese Nähe im klassischen SEO zu messen – etwa durch Analyse der übernommenen Snippets. Die Richtung ist klar: Nur wer in einem LLM inhaltlich passt und semantisch genügend ähnlich ist, hat Chancen auf Sichtbarkeit. Ist das gegeben, hilft Einzigartigkeit, Autorität und dokumentierte Expertise sowie Erfahrung. Auch das erinnert stark an klassische SEO-Konzepte, wie E-E-A-T.
Wer weiter gehen will, kann beispielsweise die Natural Language API oder die Auto ML Lösungen von Google nutzen [https://cloud.google.com/natural-language#all-features]. Damit lassen sich beispielsweise in Texten Entitäten, Tokens, Abhängigkeitsstrukturen und vieles mehr ermitteln. Zum Vergleich von eigenen Texten mit generierten Antworten ist das vielleicht etwas überdosiert, aber gerade in dieser Phase der Entwicklung spannend.
LLM-Quellenoptimierung: Wie Inhalte in Antworten landen
RAG-Systeme wie Perplexity, Bing KI oder ChatGPT mit Web-Browsing arbeiten zweistufig: Sie recherchieren Inhalte – und generieren auf dieser Basis Antworten.
Welche Quellen dabei verwendet werden, hängt nicht nur von der inhaltlichen Qualität ab, sondern auch davon, wo und wie diese Inhalte im Netz auffindbar sind. Sichtbarkeit reicht nicht – entscheidend ist, ob die KI sie versteht, verarbeitet und als zitierwürdig einstuft.
Ähnlich, wie schon im Kapitel «Was macht Inhalte LLM-relevant» beschrieben, zeigt sich folgendes:
- Inhalte in gut strukturierten, thematisch passenden Portalen oder Medien haben höhere Chancen, berücksichtigt zu werden.
- Klare Struktur, saubere Formatierung und verständliche Sprache machen es LLMs einfacher, den Inhalt maschinell zu erfassen.
- Elemente wie Definitionen, Abgrenzungen, Checklisten oder Modelle lassen sich effizient extrahieren – darum werden sie häufig eingebaut.
- Quellen mit guter Reputation – etwa Wikipedia, Reddit und Fachmedien mit LLM-Partnerschaften (z. B. The Guardian, New York Times, im Deutschsprachigen Raum bekanntermassen z.B. die Springer-Medien) – gelten als besonders zugänglich für generative Systeme.
- Auch gezielte Erwähnungen in Dossiers, Listen, Rankings oder Expertenartikeln wirken wie semantische PR-Signale. Sie verknüpfen Marke und Thema – und erhöhen so die Relevanz im Kontext von AI-Antworten.
Ein Praxisbeispiel: Eine Website erklärt den Unterschied zwischen USP und UVP – sauber gegliedert, einfach formuliert, mit Zwischenüberschriften und Beispielen. Ergänzend erscheint die Marke in einem Fachportal oder Branchenranking, das in AI Overviews oder bei Perplexity regelmässig zitiert wird. Diese Kombination aus Klarheit und Quellenautorität erhöht die Chance, in einer Antwort genannt zu werden.
Klar ist: Niemand kann erzwingen, in einer LLM-Antwort aufzutauchen. Aber die Voraussetzungen lassen sich gezielt verbessern. LLM-Quellenoptimierung ist keine exakte Wissenschaft – aber eine Möglichkeit, um Inhalte auffindbarer, lesbarer und zitierfähiger zu machen.
Wie wird eine Website LLM-ready?
Viele Fragen rund um LLMO sind inhaltlich getrieben – aber die technische Basis entscheidet oft darüber, ob Inhalte einer Website überhaupt verarbeitet werden. Vor allem bei Systemen mit RAG-Anbindung (z. B. Perplexity, Bing, ChatGPT mit Browsing) ist sie ein zentraler Faktor, ob und wie Inhalte berücksichtigt werden.
Noch ist wenig definitiv belegt, aber aus den bisherigen Beobachtungen lassen sich einige Anhaltspunkte ableiten.
Schnelle Ladezeiten (unter 500ms)
AI Overviews reagieren empfindlich auf Performance. Seiten mit langer Antwortzeit (z. B. >500 ms TTFB) tauchen in manchen Tests seltener als Quelle auf. Ob das kausal ist – offen. Aber Geschwindigkeit schadet bekanntlich nie.
Crawlbarkeit für LLM-relevante Bots
Der Zugriff durch CCBot (Common Crawl), Bingbot oder andere spezialisierte Crawler ist hingegen definitiv eine Voraussetzung, um überhaupt im Retrieval-Pool zu landen. Wer diese blockiert, ist nicht Teil der Quelle – weder im Training noch im Echtzeit-Zugriff.
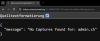
Aktuell sehen wir viele Websitebetreiber, die (fälschlicherweise oder schlicht zu gut gemeint?) in der robots.txt alle möglichen Bots ausschliessen. Irgendwann werden die sich wundern – wenn nicht jetzt schon –, warum sie in den Antworten nicht vorkommen.
Beispiel gefällig?
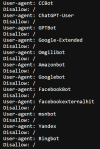
Ob das wirklich so gewollt ist? Immerhin darf die Seite nun weder von für die normale Google-Suche (=Googlebot) , noch fürs Training von Google Gemini (=Google-Extended[https://developers.google.com/search/docs/crawling-indexing/google-common-crawlers?hl=de#google-extended]) oder Bing (=Bingbot) gecrawlt werden – und OpenAI darf sie weder für das nächste Foundational Model (GPTBot oder über Common Crawl via CCBot) noch für RAG (ChatGPT-User) nutzen. Hoppla!?
Strukturierte Inhalte
Listen, H2/H3-Hierarchien, FAQs – alles, was die semantische Verarbeitung erleichtert, scheint hilfreich. Das deckt sich mit dem, was wir auch aus klassischem SEO kennen. Ob’s für LLMs gleich wichtig ist? Erste Studien weisen zumindest darauf hin.
Duplicate Content
Wenn Inhalt mehrfach im Netz zu finden ist (z. B. via Syndizierung oder White-Label-Artikel), stellt sich die Frage: Wer wird als «Original» erkannt? Canonical-Tags können helfen – aber das ist im LLM-Kontext noch wenig untersucht.
Konsistenz statt Kosmetik
Wenn Google beginnt, Meta-Descriptions automatisch zu ersetzen, kann das ein Hinweis auf mangelnde semantische Nähe sein. Ein Indiz – kein Urteil. Aber einer der Punkte, die sich beobachten lassen.
Sichtbarkeit in relevanten Quellen
LLMs greifen oft auf bekannte, gut strukturierte Portale zurück. Wer dort verlinkt oder erwähnt wird, erhöht seine Chancen. Was genau als «relevant» gilt, variiert je nach Modell – aber ein Link von einem Fachmedium war noch nie verkehrt.
Tipp: Ob die eigene Website bereits Traffic aus LLMs kriegt oder nicht, lässt sich relativ einfach in Google Analytics GA4 und dann in Google Looker Studio darstellen. Dafür wird der Referral-Traffic aus LLMs kenntlich gemacht und ausgewertet.
LLM Visibility Monitoring: Wer wird genannt – und warum?
Früher bot die Google Search Console Einblick in gut laufende Keywords. Heute stellt sich eine neue Frage: Wird eine Marke, ein Begriff oder eine Quelle von Sprachmodellen überhaupt erwähnt?
Sichtbarkeit in Large Language Models (LLMs) funktioniert anders. Sie basiert nicht auf Rankings, sondern auf Prompt-Antworten – in denen bestimmte Marken, Begriffe oder Quellen genannt werden. Oder eben nicht.
Das Monitoring dieser Nennungen ist ein neues Feld. Noch ungenau. Noch lückenhaft. Aber hochspannend.
Worum geht’s konkret?
LLM Visibility Monitoring beobachtet:
- Wird eine Marke in den Antworten erwähnt?
- Werden Inhalte als Quelle verwendet?
- Tauchen Seiten in AI Overviews oder RAG-Ergebnissen auf?
- Wie unterscheiden sich die Modelle (ChatGPT, Perplexity, Claude etc.) in der Darstellung?
- Wie sichtbar ist die Konkurrenz?
Erste Tools – und grosse Unterschiede
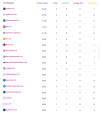
Tools wie Peec [https://peec.ai/], Otterly [https://otterly.ai/], Profound [https://www.tryprofound.com/], Dejan AI Rank [https://airank.dejan.ai/] – und mit grösster Wahrscheinlichkeit bald auch die grossen SEO-Plattformen wie Sistrix, Semrush oder Conductor (wenn denn die Gerüchte und Ankündigungen stimmen) – helfen, Antworten auf diese Fragen zu finden.
Diese Tools messen, wie und wo Marken in AI-Suchergebnissen auftauchen – etwa bei ChatGPT, Perplexity, Gemini oder in Google AI Overviews. Sie bieten Funktionen, die sich wie folgt zusammenfassen lassen [https://otterly.ai/blog/10-best-ai-search-monitoring-and-llm-monitoring-solutions/]:
- Tracking von Markennennungen & Sichtbarkeit in AI-Antworten
- Analyse von Tonalität, Quellen & Verlinkungen
- Wettbewerbsvergleiche & Optimierungshinweise
- Alerts bei Veränderungen oder Reputationsrisiken
Diese Features sind noch nicht Standard und alle Tools werden im Moment rasant ausgebaut. Es lohnt sich, mehrere zu testen und deren Entwicklung zu beobachten, bevor eines beschafft wird.
Erste Tests mit solchen Tools zeigen enorme Unterschiede in den Ergebnissen:
- ChatGPT nennt gewisse Marken häufig – andere nie.
- Perplexity nutzt andere Quellen als Claude oder Bing.
- Einige Systeme verlinken direkt auf Websites, andere geben nur Text aus.
Die Sichtbarkeit ist also nicht nur modell-, sondern auch themenabhängig. Ein LLM kann eine Marke in einem Themenfeld erwähnen – und im nächsten komplett ignorieren.

Wichtige Erkenntnisse
- Sichtbarkeit ist nicht fair verteilt: Wer in den Trainingsdaten oder bekannten Quellen vorkommt, hat Vorteile.
- Sichtbarkeit ist nicht stabil: Prompt-Ergebnisse können sich ändern – auch ohne jede Veränderung auf der eigenen Website.
- Sichtbarkeit ist nicht vollständig steuerbar – aber beeinflussbar: durch LLM-Quellenoptimierung, strukturierte Inhalte und Präsenz in vertrauenswürdigen Quellen.
Ganz wichtig: Eine einzelne Abfrage sagt wenig aus. Ich erkläre das jeweils so: Das ist, als würde ein Würfel einmal geworfen – und danach behauptet, er zeige immer eine 2. Die anderen Zahlen existieren, sie wurden nur (noch) nicht gesehen. Erst eine grössere Zahl an Würfen – bzw. in dem Fall Prompts – macht statistische Muster sichtbar und zeigt, ob bestimmte Begriffe oder Marken wirklich nicht vorkommen.
LLMO Massnahmen konkret
LLMO ist nicht irgendwann in Zukunft relevant – sondern heute. Erste Auswirkungen auf die Sichtbarkeit von Marken, Inhalten und Themen in generativen Antworten sind selbst in unseren Kundenprojekten bereits erkennbar. Und auch wenn vieles noch in Bewegung ist, gibt es Ansatzpunkte, um die eigenen Chancen gezielt zu verbessern.
Inhalte prüfen – und überarbeiten
Vorhandene Inhalte zu typischen Prompt-Themen (z. B. Vergleiche, Erklärungen, Checklisten) lohnen einen Reality-Check:
- Sichtbarkeit in LLMs gegeben? → LLM Visibility Monitoring
- Inhalt maschinenlesbar? → Struktur, Formatierung, Klarheit
- Semantische Nähe zu AI Overviews vorhanden? → Cosine Similarity
Falls der Test nicht wie gewünscht ausfällt: Inhalt überarbeiten. Klarer schreiben. Begriffe definieren. Zitate und Daten ergänzen. Ziel: Verständlichkeit für Menschen – und für Maschinen.
LLM-Quellenoptimierung gezielt einsetzen
LLMs greifen auf bekannte Quellen zurück – Fachportale, Verzeichnisse, Medien. Wer dort erwähnt oder verlinkt ist, taucht mit höherer Wahrscheinlichkeit in Antworten auf.
Fragen zur Einordnung:
- Welche Seiten werden oft als Quelle genannt?
- Woher beziehen Gemini, Perplexity oder ChatGPT mit Suchfunktion ihre Inhalte?
- Welche Plattformen dominieren bei generativen Antworten im jeweiligen Themenfeld?
Das hilft, gezielt an der LLM-Quellenoptimierung zu arbeiten – etwa über das direkte anpassen (lassen) von heute vom RAG bereits regelmässig genutzten Quellen. Spannenderweise ändert sich damit direkt die Antwort des LLMs. Logisch – trotzdem beeindruckend und gleichzeitig ziemlich trivial, nicht?
Wenn das noch nicht reicht klassisch weiterfahren mit PR, Gastbeiträgen und hochwertigen Inhalten mit starker Verlinkung.
Das erinnert an Outreach-Kampagnen, Content Seeding, Sponsored Content und die damit verbundenen Linkanalysen im klassischen SEO. Nur dass diesmal nicht die Aufmerksamkeit der User das primäre Ziel ist, sondern diejenige der LLMs. Folgt nun also eine Zeit des Marketing und PR für RAGs – in Anbetracht der Unterschiede der Linkquellen sogar Marketing und PR für jedes RAG individuell?
Entitäten und Kontexte stärken
- Fokus auf Entitäten statt Keywords – also Konzepte, Marken und Themen
- Einheitliche Verwendung dieser Entitäten über alle Inhalte hinweg
- Tools wie Google NLP API helfen, relevante Entitätsbeziehungen sichtbar zu machen [https://cloud.google.com/natural-language#demo]
Marke und Thema kombinieren
Relevante Marken werden oft genannt, wenn sie inhaltlich mit einem Thema verknüpft sind. Heisst: Marke und Thema gehören in denselben Satz – möglichst häufig, aber natürlich.
Beispiele:
- «iqual ist eine Internetagentur mit Fokus auf SEO und LLMO.»
- «Für barrierefreie Websites greifen wir auf die WCAG-Richtlinien zurück – iqual begleitet Organisationen von der Analyse bis zur Umsetzung.»
So entstehen Kookkurrenzen, die Modelle mit Marken verknüpfen – ein zentrales Prinzip in LLMO [https://upload-magazin.de/63519-llmo-geo-gaio/].
Mit Prompts testen und lernen
Ob Inhalte von LLMs erkannt oder verwendet werden, lässt sich mit gezielten Prompts testen. Kein Ersatz für systematisches Monitoring – aber ein sinnvoller Ausgangspunkt.
Beispielhafte Prompts im Umfeld eines Reisebüros:
- «Was sind gute Reiseziele für Familien mit kleinen Kindern?»
- «Welches Reisebüro in der Schweiz ist auf nachhaltige Reisen spezialisiert?»
- «Was ist der Unterschied zwischen Pauschalreise und Individualreise?»
- «Welche Anbieter bieten Rundreisen für Familien an?»
Einzelne Antworten sollten nicht überbewertet werden. Erst eine grössere Anzahl an Prompts über einen längeren Zeitraum – das Beispiel mit dem Würfel lässt grüssen – zeigt, welche Begriffe, Marken oder Inhalte regelmässig auftauchen.
Fragen zur Auswertung:
- Werden konkrete Marken oder Websites genannt?
- Tauchen Inhalte aus einer spezifischen Branche oder Region auf?
- Wird auf vertrauenswürdige Quellen verlinkt?
Inhalte sinnvoll bündeln und verlinken
RAG-Systeme greifen bevorzugt auf strukturierte, in sich geschlossene Inhalte zurück. Die Wahrscheinlichkeit, dass eine einzelne Unterseite vollständig gelesen wird, ist gering.
Deshalb:
- Inhalte bündeln, z. B. in einem Ratgeber oder Content-Hub
- intern verlinken – mit sprechenden Linktexten
- ein klares, thematisches Gerüst schaffen
Das erleichtert den Modellen das Erfassen, Einordnen und Verwerten der Inhalte.
Risiken, Grenzen und offene Fragen
LLMO ist ein spannendes Feld – aber keine exakte Wissenschaft. Klassische SEO bezeichnete Karl Kratz treffend als: «Professionelles Zocken gegen eine Blackbox, die morgen weg sein kann.» Vermutlich lässt sich das eins zu eins auf LLMO übertragen.
Wer Inhalte oder Marken sichtbar machen will, bewegt sich in einem System, das sich laufend verändert. Vieles ist möglich, einiges nötig – vieles bleibt aber unklar.
Training ≠ Realität
Die Trainingsdaten grosser Sprachmodelle sind nicht öffentlich – weder bei GPT, Claude, Gemini noch Mistral. Welche Inhalte wirklich eingeflossen sind? Unbekannt. Selbst eine starke Online-Präsenz garantiert nicht, Teil eines Foundational Models zu sein.
Ein Beispiel: In einem Test zeigte sich, dass im Common Crawl zwar einzelne Seiten von sbb.ch enthalten sind – aber keine einzige von admin.ch. Die wohl offiziellste Website der Schweiz fehlt in einem Datensatz, der nachweislich von vielen LLMs zum Training verwendet wird.
Und das, obwohl Common Crawl riesig ist: über 250 Milliarden Seiten, gesammelt seit 2007, frei verfügbar, zitiert in über 10’000 wissenschaftlichen Publikationen – und jeden Monat kommen 3 bis 5 Milliarden neue Seiten hinzu [https://commoncrawl.org/].
Ist das fragwürdig? Vielleicht. Eines ist aber klar: Es ist einfach so.
Einfluss auf Antworten lässt sich also nicht direkt nehmen – sondern nur indirekt über das, was öffentlich verfügbar, auffindbar und maschinenlesbar ist.
Im Fall von admin.ch dürften die Infos letztlich über die andere Datenquellen wie Wikipedia, Reddit, Stack Overflow oder Medienpartnerschaften reingekommen sein, die explizit für Trainingszwecke genutzt oder lizenziert wurden.
Kein Konsens – keine Kontrolle
LLMs nennen, was sie für wahrscheinlich und passend halten. Das bedeutet:
- Es lässt sich nicht erzwingen, genannt zu werden.
- Es lässt sich nicht kontrollieren, wie etwas genannt wird.
- Es lässt sich nicht verhindern, dass Mitbewerber auftauchen – auch wenn die Inhalte besser wären.
Die Modelle funktionieren probabilistisch, nicht gerecht.
Sichtbarkeit ist flüchtig
Heute genannt – morgen ignoriert? Das kann passieren. Prompt-Antworten basieren nicht auf festen Rankings, sondern auf Kontext, Modellversion, Zeit und Zufall. Einzelne Treffer können trügen.
Selbst bei vollkommen identischen Prompts sind Wiederholungen erforderlich – viele AI-Modelle nutzen Temperatur oder Randomisierung. Sichtbarkeit muss über viele Durchläufe aggregiert werden, um belastbare Aussagen zu treffen.
LLM Visibility Monitoring hilft, Muster zu erkennen. Aber es gibt (noch) keine stabile Metrik wie «#1 bei Google» oder «in den Top 10 bei Bing».
Aufwand vs. Einfluss
Viele Massnahmen zur LLM-Optimierung kosten Zeit, Geld und Know-how: bessere Inhalte, gezielte PR, saubere Technik, Tests und Monitoring. Der Einfluss? Bleibt oft indirekt – und nicht immer messbar.
Gerade bei kleineren Themen oder Nischen dürfte sich der Aufwand lohnen. In grossen Märkten dagegen dominieren oft jene mit stärkerer Medienpräsenz, PR oder Marke. Aber ehrlich: War es im klassischen SEO wirklich anders? Nein.
Missbrauch & Ethik
LLM-Quellenoptimierung wirft auch Fragen auf:
- Wo liegt die Grenze zwischen Optimierung und Manipulation?
- Was, wenn gezielt Inhalte für KI (um)geschrieben werden, um Aufmerksamkeit oder eine bestimmte Antwort zu erzwingen?
- Was, wenn KI bevorzugt nennt, was oft genannt wird – und damit die Grossen noch grösser macht?
Das Feld ist jung. Noch gibt es keine Standards, keine Ethikrichtlinien, keine «LLMO-Guidelines» wie bei Google. Erste «Black Hat LLMO»-Taktiken sind bereits beobachtbar – etwa durch gezielte Erwähnungen in Trainings-relevanten Foren oder massenhaft gekaufte und manipulierte Reddit-Beiträge. Das Ganze fühlt sich ähnlich an, wie in der SEO vor 15 oder 20 Jahren.
Und jetzt?
LLMO ist aus Sicht von iqual eine der spannendsten Entwicklungen im digitalen Marketing seit Jahren. Endlich verändert sich wieder etwas grundlegend. LLMO ist noch nicht laut, nicht überall sichtbar – aber mit wachsendem Einfluss auf Sichtbarkeit, Wahrnehmung und Wettbewerb. Wer Inhalte erstellt, kommuniziert oder gefunden werden will, kommt an Large Language Models nicht mehr vorbei.
Das bedeutet nicht, dass Strategien sofort umgeworfen oder hektisch neue Tools eingeführt werden müssen. Nicht jedes Unternehmen muss jetzt schon LLM-optimieren, Prompts testen oder Sichtbarkeitsdaten tracken. Aber es lohnt sich, die Mechanismen zu verstehen – und dort aktiv zu werden, wo es sinnvoll ist. Denn eines zeichnet sich ab: Wer versteht, wie LLMs Inhalte auswählen und verwenden, wird künftig eher Teil von Antworten sein.
Wir bei iqual beobachten, testen und experimentieren – und lernen täglich dazu. Denn vieles spricht dafür, dass Sichtbarkeit künftig anders funktioniert als bisher. Oder aber LLMO wird das neue SEO. Mit beidem können wir als LLMO-Agentur sehr gut leben. :)












